SEI in 2026: Scripts, Strategies, and Open Questions
At any given time, the Script Encoding Initiative has upwards of a dozen research projects in progress, aimed at including new scripts in the Unicode Standard. Because each script presents its own technical, historical, and community-specific questions, it can be difficult to see the shape of the work as a whole. What follows here is an overview of our planned near-term work by region: the scripts under investigation, the collaborators involved, and the kinds of decisions we’re navigating as we identify the right approaches for encoding these scripts.
Africa
| Script | Region | Period | Languages | Script Type | Collaborators | Status |
|---|---|---|---|---|---|---|
| Masaba | Mali | 1930 to Present | Bambara | syllabary | Oreen Yousuf | Revision nearly ready 2024 Proposal |
| Minim Dag Noore | Burkina Faso | 2006 to Present | Mooré | alphabet | Oreen Yousuf | Revision nearly ready 2025 Proposal |
| Ndiko Jonam | Kenya | 2009 to Present | Luo languages | alphabet | Oreen Yousuf | Revision under review 2025 Proposal |
| N’ti | Mali, Republic of Congo, Ivory Coast | 1985 to Present | Soninke | alphabet | Ibrahima Ceesay, Oreen Yousuf | Revision under review 2025 Proposal |
| Odùduwà | Benin, Nigeria | 2016 to Present | Yoruba | alphabet | Vyshantha Simha, Oreen Yousuf | Revised proposal planned 2025 Proposal |
The majority of the scripts we’re tackling from Africa are new inventions. They range from Masaba, invented just under a century ago, to Odùduwà, invented in 2016. For such scripts, the challenge is to demonstrate two things: stability, that the characters’ shapes and meanings have remained consistent over time, and adoption, that the script has been embraced by a user community.
While it’s easy to group these uniformly under the umbrella of “modern neographies,” or newly-invented scripts, in fact the scripts vary quite a bit in intention and use. A script like Masaba is used by a few hundred people in rural villages – perhaps suggesting minimal adoption at first glance. However, it seems to have been used continuously since its invention, certainly outliving the creator, and for some of its users, is the only script with which they are literate. This suggests a high level of success in carrying out what the script was intended to do.



In contrast, Ndiko Jonam, also known as Luo Lakeside, mirrors the pattern of more “viral” recent inventions, catching on with swaths of people in dense areas and spurring material investment in the script, evidenced in things like fridge magnets of the letters, representing a different kind of success.
The challenge for us, and for Unicode standards-makers, is to determine what kind of justification is “enough” – what nature of evidence convinces that these newer inventions are here to stay and that users desire to communicate in them over the internet. We’re still in the midst of learning more about this class of cases, but thus far believe the candidates above are worth investigating further.1


Middle East
| Script | Region | Period | Languages | Script Type | Collaborators | Status |
|---|---|---|---|---|---|---|
| Book Pahlavi | Iran | 200 to 1100 CE | Middle Iranian | abjad | Anshuman Pandey, Roozbeh Pournader, Arash Zeini | Revised proposal planned 2024 Proposal |
| Linear Elamite | Iran | 2300 to 1850 BCE | Elamite | logosyllabary, semisyllabary | François Desset, Sina Fakour, Thomas Huot-Marchand, Anshuman Pandey | Revised proposal planned 2021 Proposal |
| Persian Siyaq | Iran | 900 to 1900 CE | Persian | numbers | Kourosh Beigpour, Anshuman Pandey | Revision nearly ready 2021 Proposal |
| Proto-Elamite | Iran | 3100 to 2900 BCE | Unknown | logosyllabary | Anshuman Pandey | Revised proposal planned; to follow Linear Elamite 2020 Proposal |
| Proto-Sinaitic | Egypt | 1850 to 1550 BCE | Unknown Canaanite language | abjad | Anshuman Pandey | Proposal nearly ready 2019 Report |
The Middle Eastern scripts on our docket are all historic, which present a unique set of challenges. One of the central tenets of the Unicode Standard is that it encodes only characters, not glyphs. Character is meant to refer to the abstract notion of a unit of a writing system, roughly equivalent to a grapheme. Glyphs, on the other hand, are considered to be the visual variations that map more closely to style than meaning. These variations can be handled by different font options, rather than unique encodings.

This principle proves difficult to apply for more complicated script types, and specifically for ancient scripts where scholars may not agree upon or know what the core constitutive character is from a collection of similar-looking markings. Our strategy here is to only encode scripts once the relevant scholarly community achieves consensus on a repertoire. Characters do not even need to be deciphered, but there needs to be an agreed-upon inventory that is labeled and recognized in a consistent way.
For several of the ancient scripts above (Linear Elamite, Proto-Elamite, Proto-Sinaitic), there have been recent breakthroughs in scholarly understanding that are driving these projects forward. For the two relatively younger scripts, our current task involves reviewing sources for additional attestations before finalizing the repertoire for Persian Siyaq, and homing in on a character repertoire that will enable users to represent the complexities of Book Pahlavi using a simple encoding model.
Historic scripts differ most significantly from modern ones in that the contemporary users are quite specialized: they are typically scholars looking to publish commentary or digitize materials. The question is whether Unicode’s current encoding strategy works for them – to what extent is important information lost in abstracting to “characters”? As we hear of examples of scholars continuing to use ad hoc methods to suit their needs, resorting to images, hacked fonts, or Unicode’s private use area, they raise the question of what approach should be used moving forward.

Americas
| Script | Region | Period | Languages | Script Type | Collaborators | Status |
|---|---|---|---|---|---|---|
| Classic Maya Hieroglyphs | Mexico, Guatemala, Belize, Honduras | 250 to 900 CE | Mayan | logosyllabary | Alexandre Bassi, Andrew Glass, Gabrielle Vail | Font work underway; proposal to follow |
| Codical Maya Hieroglyphs | Mexico, Guatemala, Belize, Honduras | 1100 to 1519 CE | Mayan | logosyllabary | Andrew Glass, Carlos Pallan, Céline Tamignaux | Proposal nearly ready |
Continuing along the historic theme, we have two ongoing projects in the Americas, both aimed at representing Maya hieroglyphic writing. Maya writing is incredibly complex. The ornate signs are agglomerated into blocks which generally follow a 6×6 grid. These blocks are usually arranged in paired columns. Rendering the large sign repertoire and block arrangements echo the complexity of Egyptian Hieroglyphs, simpler in some respects and more complex in others. A special challenge for Maya writing is that the glyphs need to precisely touch within a block, leaving no room for error.

The first project of ours is Codical Maya, done in conjunction with the Unicode Consortium. Because there is a bounded set of codices and characters from the post-Classic period, these represent a tractable way to first establish the Maya code block. The follow-on project is Classic Maya, which will be proposed as extensions to that initial block. The potential corpus from the Classic period is quite sprawling, so the approach here is to prioritize characters that would allow the representation of key texts used by scholars.2 The hope is that future extensions would continue to add material from the Classic period.


These projects have thus required extensive coordination with Unicode standards-makers (the leads on these projects began meeting with standards-makers over a decade ago to find a workable strategy for this proposal), and interdisciplinary input from archeologists, type designers, and font engineers. Andrew Glass, product manager at Microsoft and our frequent collaborator, serves as an essential linchpin across these projects, working in parallel with both expert teams to hone a common strategy for the encodings.
Southeast Asia
| Script | Region | Period | Languages | Script Type | Collaborators | Status |
|---|---|---|---|---|---|---|
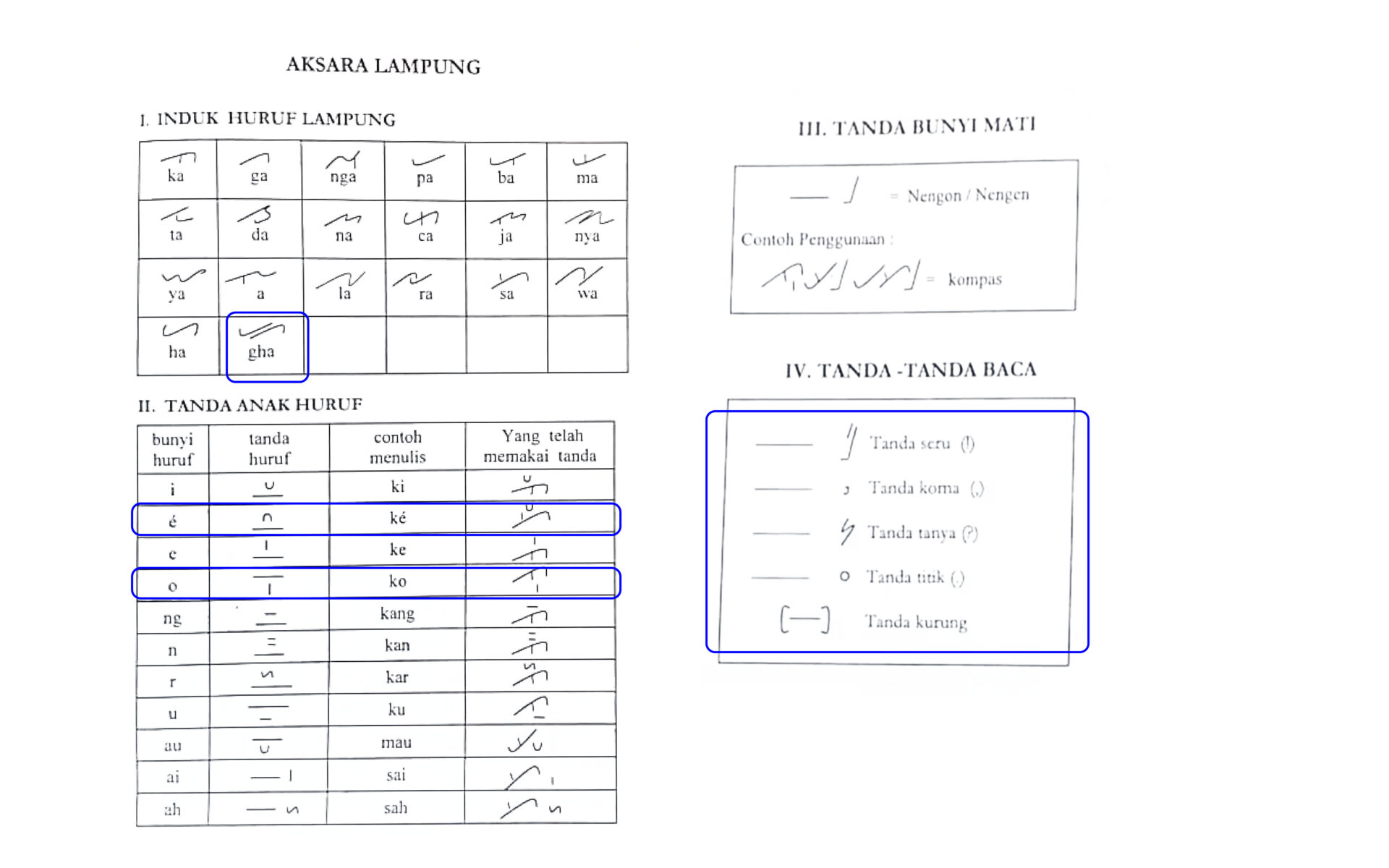
| Lampung | Sumatra, Indonesia | 1600 to Present | Lampung | abugida | Febri Muhammad Nasrullah | Revision under review 2025 Proposal |
| Kerinci | Sumatra, Indonesia | 1370 to Present | Kerinci | abugida | Febri Muhammad Nasrullah, Anshuman Pandey, Aditya Bayu Perdana | Revised proposal planned 2016 Proposal |
| Kulitan | Pampanga, Philippines | 1600 to Present | Kapampangang | abugida | Anshuman Pandey, Julie Sayo | Proposal nearly ready 2015 Report |
| Rejang | Sumatra, Indonesia | 1700 to Present | Malay, Bengkulu, Rejang | abugida | Ariq Syauqi | Script published in Unicode 5.1 (2008). Comments on codeblock underway 2025 Review |
From Southeast Asia, we are working on one script from the Philippines (Kulitan), and a cluster from Indonesia (Lampung, Kerinci, Rejang). All of these are examples of historic scripts that have found serious modern interest. Such cases present their own challenges. Which orthography should we hold fidelity to, the version attested in historic manuscripts or a modern reform that is part of revitalization efforts today? If both, should the orthographies share an encoding or be treated separately by Unicode? In the past, such questions have elicited strong opinions, sometimes leading to protracted conflicts that delay encoding.



Our proposal work on Kulitan will be supported by research fellow Julie Sayo.3 For this, we are in the midst of collecting documentation on modern use and determining what kind of encoding model makes sense for this complicated script – does it work more like Devanagari or Hangul in how the characters are formed?
The Indonesian proposal projects include collaborations with current and past research fellows Febri Muhammad Nasrullah and Ariq Syauqi, working with our core proposal team.4 Some relevant matters here include how modifying characters should be classified – are they beside or above the base character, which can be hard to tell when pulling from handwritten manuscript attestations – and what sequence we anticipate users to type in. These are recurring questions for Indic scripts, which have many combining and reordered pieces that must be handled by Unicode in coordination with input methods and text rendering software.

South Asia
| Script | Region | Period | Languages | Script Type | Collaborators | Status |
|---|---|---|---|---|---|---|
| Box-Headed | Central and Southern India | 200 to 800 CE | Sanskrit, Kannada | abugida | Jan Kučera, Biswajit Mandal | Revised proposal planned 2024 Proposal |
| Kurukh Banna | Odisha, India | 1991 to Present | Kurukh | abugida | Biswajit Mandal, Anshuman Pandey | Revised proposal planned 2024 Proposal |
| Vatteluttu | South India | 400 to 1500 CE | Tamil, Malayalam | abugida | Biswajit Mandal, Anshuman Pandey | Revision nearly ready 2016 Proposal |
| Zou | Northeastern India | 1952 to Present | Zomi, Zou, Zo | alphabet | Biswajit Mandal, Anshuman Pandey | Revision nearly ready 2010 Proposal |
Closing out our list, we have a mix of modern and historic scripts originating in South Asia. Amongst the modern, we have Kurukh Banna. Kurukh Banna was invented for the Kurukh language and is used primarily in Odisha state in India. A different script for the same language, Tolong Siki, was recently encoded in Unicode 17.0 (described in our blog post here). Though Tolong Siki benefits from official state recognition, we assessed that Kurukh Banna has reached a similar level of stability and adoption, and are thus putting it forward for Unicode inclusion. We are also working on the Zou (or Zolai) script, not to be confused with the modern Zou script from the Republic of Congo. This Zou script is also from northeastern India, a particularly active region for script invention. Our proposal authors have been accumulating evidence for this script and have been in touch with a community of users keen to use the script on digital devices.
The two historic scripts on the docket, Vatteluttu and Box-Headed, are both from South and Central India and are precursors to scripts such as Tamil, Malayalam, and Kannada. For each script, the primary decision concerns how much internal historical variation to represent explicitly. These scripts were used across several centuries, regions, and dynasties. One approach could be to delineate these different epochs and encode them as distinct scripts. The other approach could be to unify them under a general model, allowing distinctions to be handled in fonts. These decisions will also determine what the script name should be, whether described graphically (e.g. “Box-headed,” “Arrow-headed”), by dynasty (e.g. Kadamba), or something else entirely.

As you can see, the challenges facing script encoding researchers are not purely technical, though familiarity with the priorities and principles governing the text stack is necessary. But the challenges are also paleographic and philologic, ultimately requiring the development of classifications that balance historical understanding with contemporary functionality.
We do our best to work across a constellation of stakeholders, but are continually trying to incorporate broader feedback to inform the encoding process. If you have expertise on any of the scripts mentioned above, do get in touch with us.
We are able to undertake this long-horizon, intensive research because of sustained support from the Mellon Foundation and, in earlier phases, the National Endowment for the Humanities – institutions whose commitment to scholarship and the public interest makes projects like this possible.